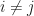In the first equation of the popular Attention is all you need paper (see also this blog post), the authors write

In this post we are going to discuss where the 
The principle of square root cancellation also appears in the Batch Norm Paper, Neural Network weight initialization (see also Xavier Uniform), and elsewhere.
The Math
Let 
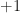
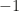

We will be interested in the simple question: what is the sum of the coordinates? For a fixed vector, we can easily compute this via

The largest this sum can be is 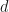
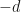
Since the vector has both
Let’s first run an experiment in python. We let 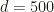

import numpy as np
import seaborn as sns
d = 500; sums = []
for _ in range(100_000):
v = np.random.choice([-1, 1], size=d)
sums.append(np.sum(v))
_ = sns.histplot(data = sums)

We see that most of the sums are quite a bit smaller than 500, and barely any are smaller than 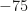
This is the so-called square root cancellation. If we take a random vector of dimension 
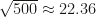
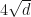
The square root cancellation heuristic asserts that “most” vectors exhibit square root cancellation. Put another way, if we come across a vector in practice, we’d expect there to be square root cancellation as in the above example.
It turns out that the example we will discuss below generalizes considerably. The only thing that really matters is that each coordinate has mean zero (which is easily remedied by translation of a fixed constant). There are also some technical assumptions that the coordinates of
Before going any deeper, let’s explain what’s going on in the aforementioned Attention is All you Need paper.
Attention is All You Need Example
In the above equation, we have

Each entries of 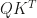

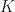

It turns out that this is the sum of 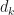
Keeping the sums from being too large helps us avoid the problem of exploding gradients in deep learning.
Back to the Math
Recall we had a vector
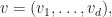
and we are interesting in what the sum is, on average. To make the question more precise, we assume each coordinate is independently generated randomly with mean zero. The key assumption is independence, that is the generation of one coordinate does not impact the others. The mean zero assumption can be obtained by shifting the values (for instance instead of recording a six sided dice roll, record the dice roll minus 3.5).
Here are some examples in python that you are welcome to check
v1 = np.random.choice([1,2,3,4,5,6],size=500) - 3.5 v2 = np.random.exponential(1,size=500) - 1 v3 = np.random.normal(0,1,size=500)
For such a vector, and

Specializing to the case where the coordinates are
One way to see this is to explicitly compute the expected value of

which is precisely $d$. This computation can be done by expanding the square and using that the covariance of two different coordinates is 0. We will put the classical computation at the end of the post for those interested.
It is a common theme in this area that working with the square of the sum is theoretically much easier than working with the sum itself.
The Central Limit Theorem
It is worth reiterating that the square root cancellation heuristic generalizes much further than the

the histplot will be normal with mean zero and variance. Put another way,
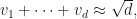
and we can quantify the 
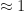
The Variance Computation
We will show
![E[ \left( v_1^2 + \cdots + v_d^2 \right) ] = \sum_{j} E[v_j^2]](https://s0.wp.com/latex.php?latex=E%5B+%5Cleft%28+v_1%5E2+%2B+%5Ccdots+%2B+v_d%5E2+%5Cright%29+%5D+%3D+%5Csum_%7Bj%7D+E%5Bv_j%5E2%5D&bg=ffffff&fg=141412&s=0&c=20201002)
Indeed,
![E[ \left( v_1^2 + \cdots + v_d^2 \right) ]= E[\sum_{ i,j} v_i v_j ] =\sum_{ i,j} E[v_i v_j ] ,](https://s0.wp.com/latex.php?latex=E%5B+%5Cleft%28+v_1%5E2+%2B+%5Ccdots+%2B+v_d%5E2+%5Cright%29+%5D%3D+E%5B%5Csum_%7B+i%2Cj%7D+v_i+v_j+%5D+%3D%5Csum_%7B+i%2Cj%7D+E%5Bv_i+v_j+%5D+%2C&bg=ffffff&fg=141412&s=0&c=20201002)
using FOIL from algebra and linearity of expectation. It is thus enough to show,
![\sum_{ i,j} E[v_i v_j ] = 0,](https://s0.wp.com/latex.php?latex=%5Csum_%7B+i%2Cj%7D+E%5Bv_i+v_j+%5D++%3D+0%2C&bg=ffffff&fg=141412&s=0&c=20201002)
for every